※"컴퓨터 구조 및 설계 6판 MIPS EDITION" 책을 간단하게 정리한 내용의 글입니다.※
4.1 서론
1장에서 봤듯이 컴퓨터 성능은 '명령어 개수', '클럭 사이클 시간', '명령어당 클럿 사이클 수(CPI)'에 의해 결정된다. 여기서 '클럭 사이클 시간'과 'CPI'는 프로세서의 구현 방법에 따라 결정된다.
이 장에서는 MIPS 명령어 집합을 두 가지 다른 방법으로 구현하여 데이터패스와 제어 유닛을 만든다.
< 구현에 대한 개요 >
- 모든 명령어의 공통 첫 두 단계
- 프로그램 카운터(PC)를 프로그램이 저장되어 있는 메모리에 보내서 메모리로부터 명령어를 가져온다.
- 읽을 레지스터를 선택하는 명령어 필드를 사용하여 하나 또는 2개의 레지스터를 읽는다.
- 공통 두 단계 이후
위의 두 단계 이후에 명령어 실행을 끝내기 위해 필요한 행동들은 명령어 종류에 따라 달라진다.
MIPS 명령어 집합은 단순하고 규칙적이기 때문에 여러 종류의 명령어 실행이 비슷해서 구현이 간단하다.
메모리 참조 명령어(sw, lw), 산술/논리 명령어(add, sub, AND, ...), 분기 명령어(beq, j)에서 j를 제외한 모든 명령어가 레지스터를 읽은 후에 ALU를 사용한다. ALU를 사용하는 이유와 그 이후의 행동은 명령어 마다 다르다. - MIPS 부분집합 구현의 추상적 개관

모든 명령어의 실행은 PC에 있는 명령어 주소를 명령어 메모리로 보내는 것으로 시작된다. 명령어를 가져온 후 명령어의 필드를 보고 명령어가 사용하는 레지스터 피연산자를 알아낸다. 레지스터 피연산자를 읽고, 각 명령어에 맞는 작업을 수행한다. - MIPS 부분집합의 기본적 구현 (멀티플렉서(Mux)와 제어유닛, 제어선 포함)
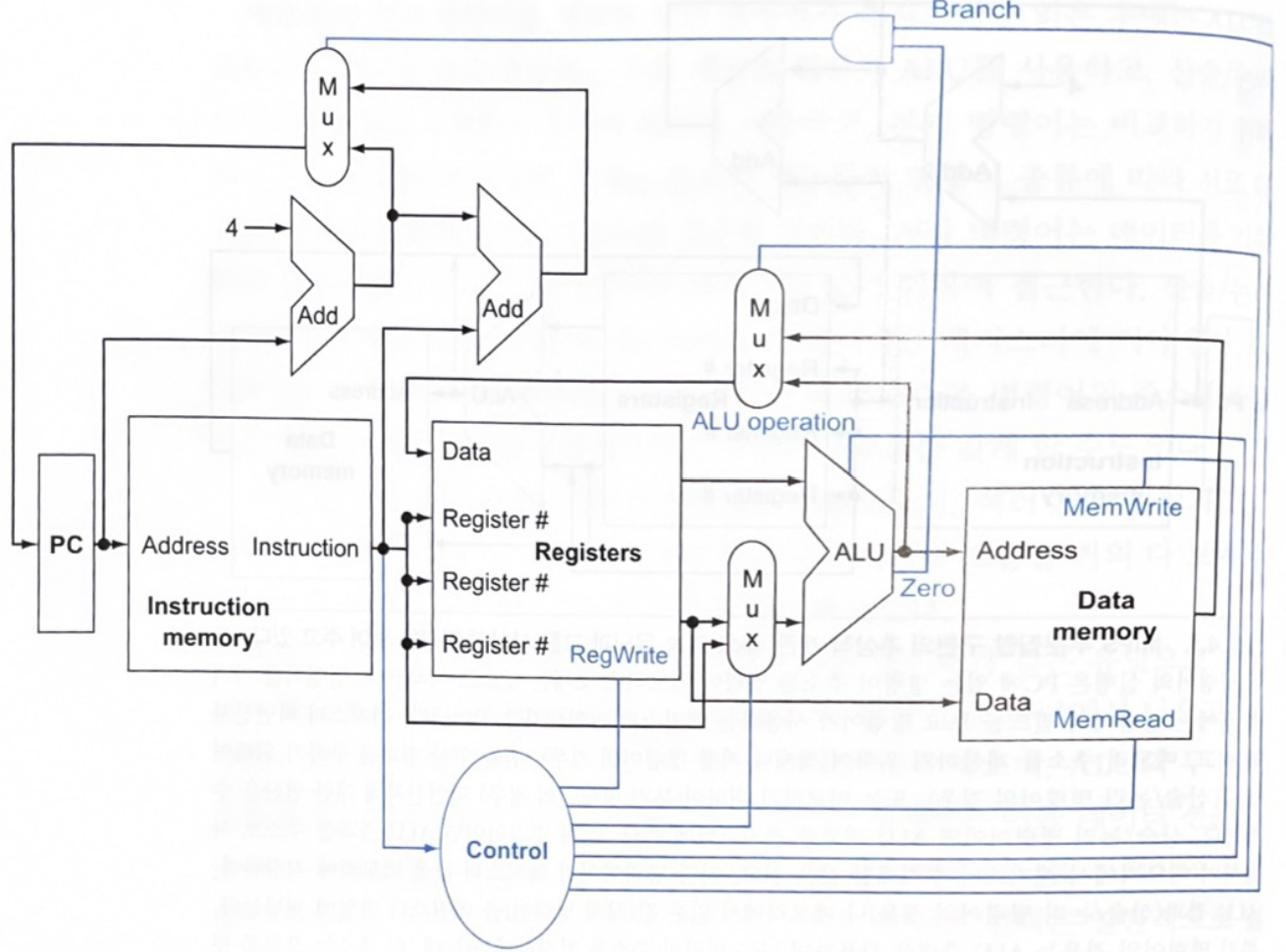
멀티플렉서(multiplexor)와 제어 유닛(control unit), 제어 선이 포함된 그림이다. 제어 유닛과 제어 선으 파랑색으로 표시되어 있다.
멀티플렉서(Mux)는 입력된 두 값 중에 제어선에 따라 하나를 고르를 데이터 선택기(data selector) 역할을 한다.
위의 그림에서 제어 유닛(control unit)은 명령어를 입력으로 받아서 기능 유닛들과 두 멀티플렉서의 제어선 값을 결정한다.
세 번째 멀티플렉서는 PC + 4와 분기 목적지 주소 중 어느 것을 PC에 써야 할지 결정한다. 이는 ALU의 Zero 출력으로 제어되고, 이 출력의 값은 beq 명령어의 비교 결과로 결정된다.(ALU의 Zero 출력과 현재 명령어가 분기 명령어라는 것을 나타내는 제어선을 AND하는 게이트에 의해 제어된다.)
4.2 논리 설계 관례
MIPS를 구현하는 데이터패스 요소는 조합 소자와 상태 소자 두 가지 종류의 논리 소자들로 구성된다.
- 조합 소자(combinational element)
데이터 값에 대해 연산을 수행하는 소자로 AND 게이트나 ALU 같은 연산형 소자를 말한다. 출력이 현재 입력에 의해서만 결정된다. 또한 내부 기억 장소가 없기 때문에 같은 입력이면 같은 출력을 낸다. - 상태 소자(state element)
소자에 내부 기억 장소가 있으면 상태를 갖게 된다. 레지스터나 메모리 같은 내부 기억 장소가 있는 소자를 말한다. 컴퓨터가 꺼졌다 켜져도, 이전의 상태 소자의 값을 다시 넣어주면 이전과 같은 상태가 된다. 즉, 상태 소자들이 컴퓨터를 완전히 특징짓는다. - 상태 소자의 특징
상태 소자는 적어도 2개의 입력과 1개의 출력을 갖는다.(논리적으로 가장 간단한 상태 소자 중 하나인 D 플립플롭은 2개의 입력과 하나의 출력을 갖는다.)
'기록할 데이터'와 '클럭'은 반드시 입력되어야 한다.
출력할 때는 이전 클럭 사이클에 기록된 값을 출력한다.
상태 소자에 언제 쓸 것인가는 클럭이 결정하지만, 상태 소자의 값을 읽는 것은 언제라도 가능하다. - 순차 회로
상태 소자를 포함하는 논리 구성 요소를 순차 회로(sequential circuit)라고 한다.
이는 이들의 출력이 입력뿐만 아니라 내부 상태(상태 소자)에 따라서도 달라지기 때문이다.
< 클러킹 방법론 >
클러킹 방법론(clocking methodology)은 신호가 읽고 쓰는 시점을 정의한다. 신호가 쓰여질 때 값이 섞이면 안되기 때문에 명확하게 언제 신호를 읽고 쓸지 정해야 한다.
- 에지 구동 클러킹(edge-triggered clocking)

에지 구동 클러킹에서 값을 읽고 쓰는 것은 클럭 에지에서만 일어난다. 클럭 에지는 Clock Cycle이 높은 값에서 낮은 값으로, 혹은 낮은 값에서 높은 값으로 변하는 지점을 말한다.
상태 소자만이 데이터 값을 저장할 수 있끼 때문에 모든 조합 논리는 상태 소자에서 입력을 받고 상태 소자로 출력을 내보낸다.조합 논리의 입력은 이전 클럭 사이클에서 상태 소자에 쓴 값이고, 출력은 다음 클럭 사이클에서 조합 논리나 상태 소자가 사용할 수 있는 값이다.
위의 그림은 조합 회로를 둘러싸고 있는 2개의 상태 소자를 보여준다. 상태 소자1에서 상태 소자2로 신호가 전달되는 데 하나의 클럭 사이클이 걸린다. 신호가 상태 소자2에 도착하는 데 필요한 시간이 클럭 사이클의 길이를 결정하게 된다.

상태 소자에 쓸 때 클럭 신호와 쓰기 제어 신호가 입력으로 들어간다. 쓰기 제어 신호가 인가(asserted: 논리적으로 높은 신호를 말한다.)되고 활성화 클럭 에지일 때만 상태 소자가 변하게 된다.
위의 그림에서 에지 구동 방법론은 한 클럭 사이클에 레지스터의 값을 읽어서 조합 회로로 보내고 다시 같은 레지스터에 쓰는 것을 허용한다.
'CS > 컴퓨터구조' 카테고리의 다른 글
| [컴퓨터구조] 4 프로세서 (4.6 파이프라이닝 개요) (0) | 2024.11.19 |
|---|---|
| [컴퓨터구조] 4 프로세서 (4.3 데이터패스 만들기) (0) | 2024.11.12 |
| [컴퓨터구조] 3 컴퓨터 연산 (3.5 부동 소수점 ~) (0) | 2024.11.05 |
| [컴퓨터구조] 3 컴퓨터 연산 3.1 ~ 3.4 (1) | 2024.10.15 |
| [컴퓨터구조] 2 명령어: 컴퓨터 언어 2.11 ~ (0) | 2024.10.15 |



