※"컴퓨터 구조 및 설계 6판 MIPS EDITION" 책을 간단하게 정리한 내용의 글입니다.※
2.1 서론
컴퓨터가 사용하는 어휘들을 명령어 집합(instruction set)이라고 한다.
명령어 집합은 아키텍처(ISA)에 따라 다르다.
2.2 하드웨어 연산
add a, b, cb와 c를 더해서 a에 넣는 명령어
여기서 add는 연산자(operator)이고, a, b, c는 피연산자(operand)이다.
MIPS 대부분의 명령어가 피연산자를 반드시 3개씩 갖도록 하고 있는데, 그 이유는 하드웨어를 단순하게 하기 위함이다.
설계 원칙 1: 간단하게 하기 위해서는 규칙적인 것이 좋다.
< 복잡한 C 치환문 번역 >
f = (g + h) - (i + j);이 코드를 MIPS 명령어로 치환하면 다음과 같다.
add t0, g, h
add t1, i, j
sub f, t0, t12.3 피연산자
어셈블리어의 산술 연산자의 피연산자는 레지스터(register)로 제한된다.
MIPS 아키텍처에서 레지스터는 32개가 존재한다.
일반적으로 32비트 아키텍처에서는 명령어의 길이가 32비트이고, 레지스터의 크기도 32비트이다. 그리고 32비트(4바이트)를 워드라고 한다.
64비트 아키텍처는 64비트(8바이트)가 1 워드가 된다.
MIPS는 32비트 아키텍처이고, 32비트(4바이트)가 1워드가 된다.
레지스터가 많아지면 전기 신호가 더 멀리까지 전달되어야 하기 때문에 클럭 사이클 시간이 길어진다. 그래서 레지스터의 개수가 많다고 좋은 것은 아니다.
설계 원칙 2: 작은 것이 더 빠르다.
< 위의 C 치환문을 레지스터 번호로 >
f = (g + h) - (i + j);C 코드
add $t0, $s1, $s2
add $t1, $s3, $s4
sub $s0, $t0, $t1컴파일러는 변수를 레지스터와 연관시켜주는 역할을 수행한다. 그래서 위와 같이 변환될 수 있다.
MIPS에서는 레지스터를 '$' 기호로 표기한다. 변수 레지스터는 '$s'로 시작하고, 임시 레지스터는 '$t'로 시작한다.
< 메모리 피연산자 >
MIPS 산술 명령은 레지스터에 있는 데이터만 가능하다. 하지만 레지스터에는 많은 데이터를 가지고 있을 수 없다.
그래서 메모리와 레지스터 간에 데이터를 주고받을 수 있는 명령어가 필요하다.
이를 데이터 전송 명령어(data transfer instruction)라고 한다. 메모리 주소를 지정해서 메모리로 접근한다.
적재(load)
메모리에서 레지스터로 데이터를 복사해오는 것을 적재(load)라고 한다.g = h + A[8]lw $t0, 8($s3)위의 명령은 $s3 레지스터에 있는 주소에 인덱스 8을 더한 메모리 위치에 있는 값을 $t0로 복사해 오라는 명령이다.
여기에서 8을 변위(offset)라고 한다.
컴퓨터는 대부분 바이트 주소를 사용한다. 즉, 주소가 1바이트(8비트) 단위로 매겨진다는 것이다.
그리고 32비트 아키텍처인 MIPS에서는 명령어를 4바이트(1워드) 단위로 저장한다. 그렇기 때문에 위의 예시에서 변위(offset)가 8인 것은 A[2]의 값을 가져온 것이다. 올바르게 작성한 코드는 아래와 같다.lw $t0, 32($s3)여기서 $s3를 베이스 레지스터라고 한다.
(※ 워드는 4바이트 단위이기 때문에 모든 워드의 시작 주소는 항상 4의 배수여야 한다. 이 요구 사항을 정렬 제약이라고 한다.)저장(store)
레지스터의 데이터를 메모리로 보내는 명령을 저장(store)이라고 한다.A[12] = h + A[8]h는 $s2에 할당되어 있고, 배열 A의 시작 주소는 $s3에 들어 있다.
lw $t0, 32($s3) add $t0, $s2, $t0 sw $t0, 48($s3)< 상수 또는 수치 피연산자 >
연산 중에 상수를 사용하는 일이 많이 있다. 하지만 기존 산술 연산자는 레지스터의 값으로만 연산을 할 수 있다.
그래서 피연산자 중 하나가 상수인 산술 연산 명령어도 제공한다. 이 상수를 수치(immediate) 피연산자라고 한다.addi $s3, $s3, 4상수 4를 더하는 명령이다.
상수에서 0은 add 명령과 함께 복사(move)할 때 쓰인다.
2.4 부호있는 수와 부호없는 수
부호있는 수가 있고 부호 없는 수가 있다. 부호 없는 수는 양수만을 표현한다.
- LSB와 MSB
MIPS에서 수를 2진수로 나타냈을 때 가장 오른쪽 비트(가장 낮은쪽 비트)를 LSB(least significant bit)라고 한다.
또한 2진수로 나타냈을 때 가장 왼쪽 비트(가장 높은쪽 비트)를 MSB(most significant bit)라고 한다. - 부호 있는 수(이진수)
모든 컴퓨터는 부호 있는 수를 2의 보수법으로 표현한다.
가장 앞의 비트(MSB)가 1이면 음수이고, 0이면 양수이다. 0인 경우가 있기 때문에 음수가 양수보다 하나 더 많다. 이를 주의해야 한다.
2의 보수법을 사용해서 MSB만 체크하면 음수인지 양수인지 알 수 있게 되었다. - 역부호화 방법
1은 0으로, 0은 1로 바꾸고 1을 더한다.
210 = 0000 0000 0000 0000 0000 0000 0000 00102
1,0바꾸기 -> 1111 1111 1111 1111 1111 1111 1111 11012
1더하기 -> 1111 1111 1111 1111 1111 1111 1111 11102 = -210
(※ 1의 보수법 방식도 있었다. 1의 보수법은 음수과 양수의 개수가 같고 0 표현 방식이 2가지이다. 1의 보수법은 덧셈기에서 한 단계를 더 필요로 하기 때문에 2의 보수법을 주로 사용한다.
1의 보수법과 2의 보수법 모드 가장 큰 양수는 0111...11112이고, 절댓값이 가장 큰 음수는 1000...00002이다.)
2.5 명령어의 컴퓨터 내부 표현
모든 명령어는 숫자로 표현할 수 있다. 그러기 위해서는 레지스터를 숫자로 표현할 수 있어야 한다.
MIPS에서는 $s0 ~ $s7을 16 ~ 23번으로, $t0 ~ $t7을 8 ~ 15번으로 매핑한다.
add $t0, $s1, $s2이런 명령어가 있을 때, $t0은 8번, $s1은 17번, $s2는 18번이 된다.
이 명령어를 10진수 숫자로 표현하면 다음과 같다.
0 / 17 / 18 / 8 / 0 / 32
명령어는 6개의 필드로 나눠진다. 이런 레이아웃을 명령어 형식(instruction format)이라고 한다. MIPS 아키텍처는 32비트 명령어를 사용한다. 32비트는 1워드이다.
또한 위처럼 명령어를 숫자로 표현한 것을 기계어라고 한다.(어셈블리어와 구분되는 이름이다.)
< MIPS 명령어의 필드 >
| op | rs | rt | rd | shamt | funct |
|---|---|---|---|---|---|
| 6 bits | 5 bits | 5 bits | 5 bits | 5 bits | 6 bits |
- op: 연산자(opcode). 명령어가 실행할 연산의 종류
- rs: 첫 번째 source 피연산자 레지스터
- rt: 두 번째 source 피연산자 레지스터
- rd: 목적지 레지스터. 연산 결과가 저장.
- shamt: 자리이동량
- funct: op 필드가 연산의 종류를 표시하면, funct 필드가 한 연산을 구체적으로 지정한다.
명령어 형식의 필드는 위와 같이 이루어져 있다. rs, rt, rd는 레지스터 번호를 나타내는데, 5bits를 통해 최대 32개의 레지스터가 매핑 가능하다.
근데 이 크기가 5bits일 경우 더 큰 수를 더해야할 때 그러지 못할 수 있다. 그래서 addi와 같이 상수가 피연산자로 들어가는 명령어들은 다른 형식의 명령어 형식(instruction format)을 사용한다.
기존에 위에서 설명한 형식을 R형식 또는 R타입이라고 하고, immediate 피연산자가 들어가는 명령어들의 형식은 I형식 또는 I타입이라고 한다.
| op | rs | rt | constant or address |
|---|---|---|---|
| 6 bits | 5 bits | 5 bits | 16 bits |
| 위는 I타입 명령어 형식이다. R타입과 다르게 I타입에서는 rt에 목적지 레지스터 번호가 들어간다. |
lw, sw, addi와 같은 명령어가 I타입에 속한다. I타입 명령어 형식 구조상 offset은 16bits이고, 그렇기 때문에 lw나 sw, addi에서 사용할 수 있는 주소나 상수는 +-215 범위에서만 가능하다.
하드웨어는 op 필드를 보고 R타입인지, I타입인지 알게되고, 나머지 필드를 어떻게 해석할 지 결정한다.
< 예제 >
A[300] = h + A[300];이를 컴파일해서 어셈블리어로 만들면 다음과 같다. (배열A의 시작 주소는 $t1에, h는 $s2에 대응)
lw $t0, 1200($t1)
add $t0, $s2, $t0
sw $t0, 1200($t1)이를 아래 표를 참고해서 기계어로 바꿔보자.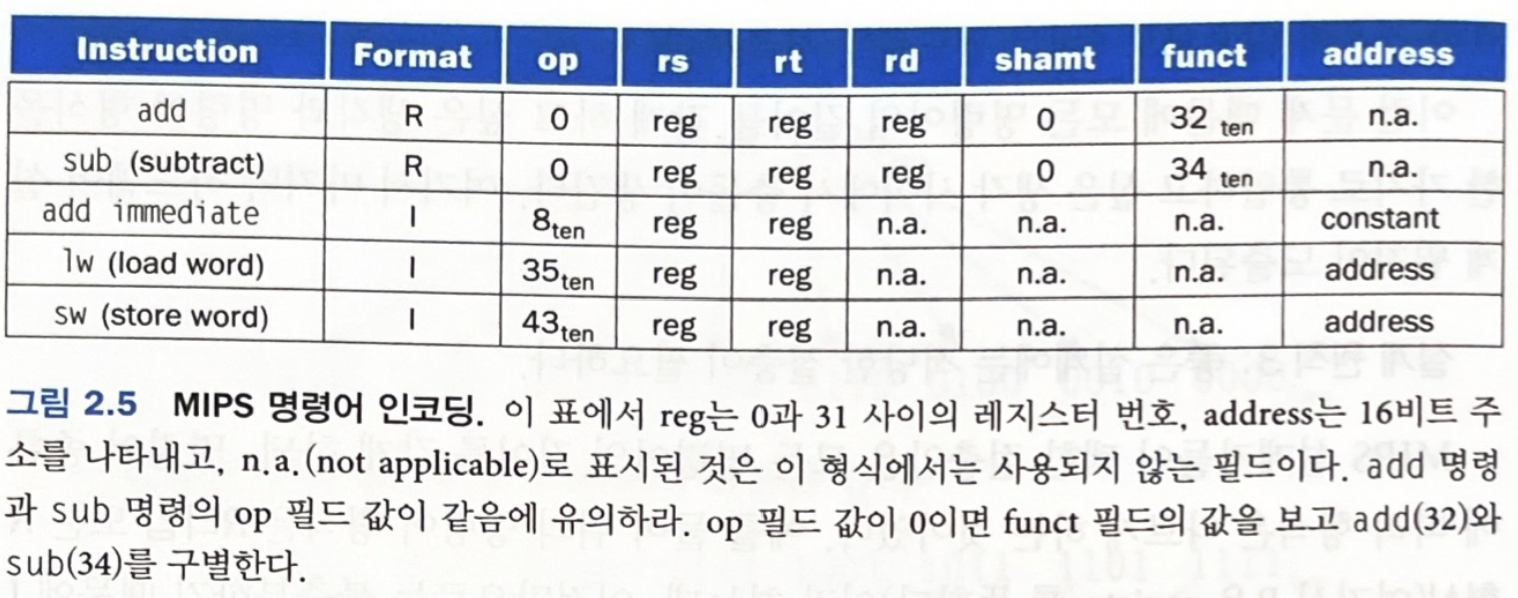
35 / 9 / 8 / 1200
0 / 18 / 8 / 8 / 0 / 32
43 / 9 / 8 / 1200
이를 이진수로 표현하면 다음과 같다.
100011 / 01001 / 01000 / 0000 0100 1011 0000
000000 / 10010 / 01000 / 01000 / 00000 / 100000
101011 / 01001 / 01000 / 0000 0100 1011 0000
결론
- 내장 프로그램의 개념
명령어를 데이터와 같이 숫자로 표현할 수 있게 되었다. 이를 통해 하나의 컴퓨터에서 여러 목적의 프로그램이 돌아갈 수 있게 되었다. 또한 컴파일러 같은 프로그램이 인간에게 편리한 형태로 작성된 코드를 기계어로 바꿀 수 있게 되었다.
'CS > 컴퓨터구조' 카테고리의 다른 글
| [컴퓨터구조] 3 컴퓨터 연산 (3.5 부동 소수점 ~) (0) | 2024.11.05 |
|---|---|
| [컴퓨터구조] 3 컴퓨터 연산 3.1 ~ 3.4 (1) | 2024.10.15 |
| [컴퓨터구조] 2 명령어: 컴퓨터 언어 2.11 ~ (0) | 2024.10.15 |
| [컴퓨터구조] 2 명령어: 컴퓨터 언어 2.6~ (1) | 2024.10.08 |
| [컴퓨터구조] 1 컴퓨터 추상화 및 관련 기술 (5) | 2024.09.17 |



